OOM 원인 분석기, 근데 이제 데드락과 스레드
시리즈로 나오지 않기를 간절히 바라며 포스팅을 시작합니다..🥲
🧨 문제 발생: Heap도 안 찼는데 OOM?

이틀에 한 번 꼴로 날라오는 OOM 발생 메일..
늘 그렇듯 원인 분석을 위해 힙 덤프 파일을 요청하려 했으나 예상 외의 답변이 돌아왔다.

실제 OOM이 발생하는 시기의 Heap 메모리 영역을 확인해보니
최대 용량으로 지정해놓은 1Gib에 한참 밑도는 상황에서 터지는 것을 알 수 있었다.
java.lang.OutOfMemoryError: Java heap space
java.lang.OutOfMemoryError: GC Overhead limit exceeded
java.lang.OutOfMemoryError: Requested array size exceeds VM
애플리케이션 내부에서 OOM이 발생하여 종료된다면, 위처럼 로그 내부에서 힌트를 얻을 수 있겠지만,
현재는 ECS가 컨테이너를 모니터링하며 전체 메모리 사용량(힙 + 네이티브 + 스택 메모리)이 지정된 한도를 넘을 경우 컨테이너를 종료하는 상황이다.
→ 따라서 어플리케이션이 로그를 남기고 죽기 전에 ECS에서 먼저 컨테이너를 죽여버려서 덤프파일도, 로그도, 아무것도 얻지 못하는 상황..
빈 손으로 털레털레 데이터독으로 들어가 APM 항목을 훑어보던 중 특이한 점을 발견할 수 있었는데
바로 스레드의 수가 비정상적으로 높다는 것
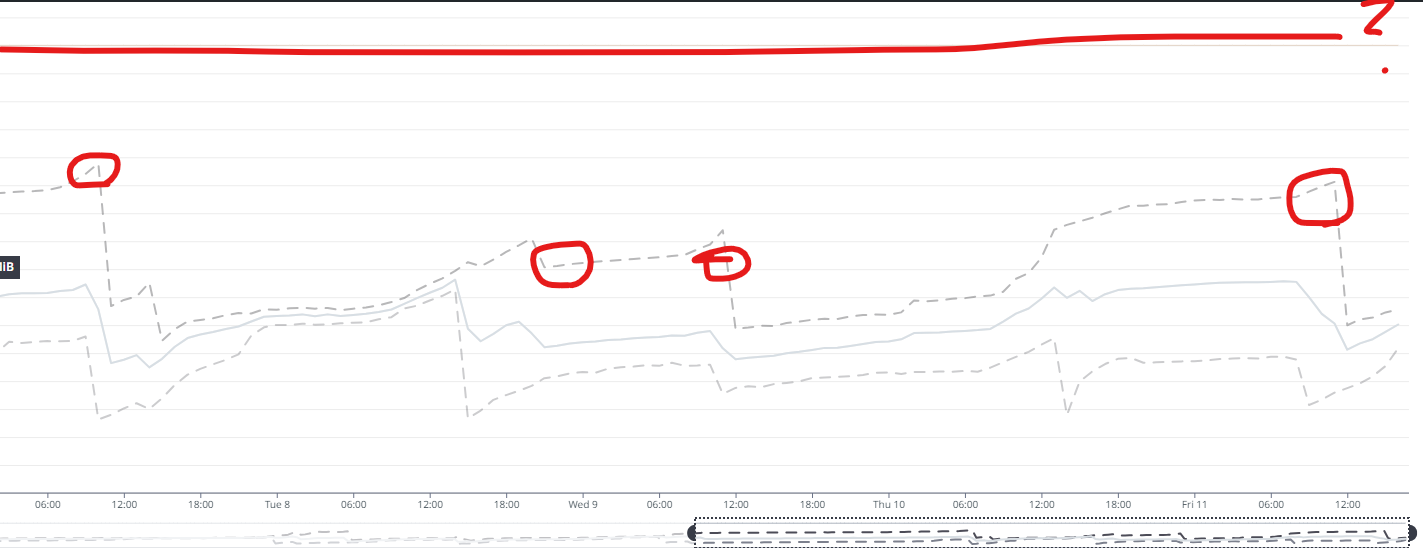
👀 단서 발견: DataDog에서 보인 ‘스레드 수’
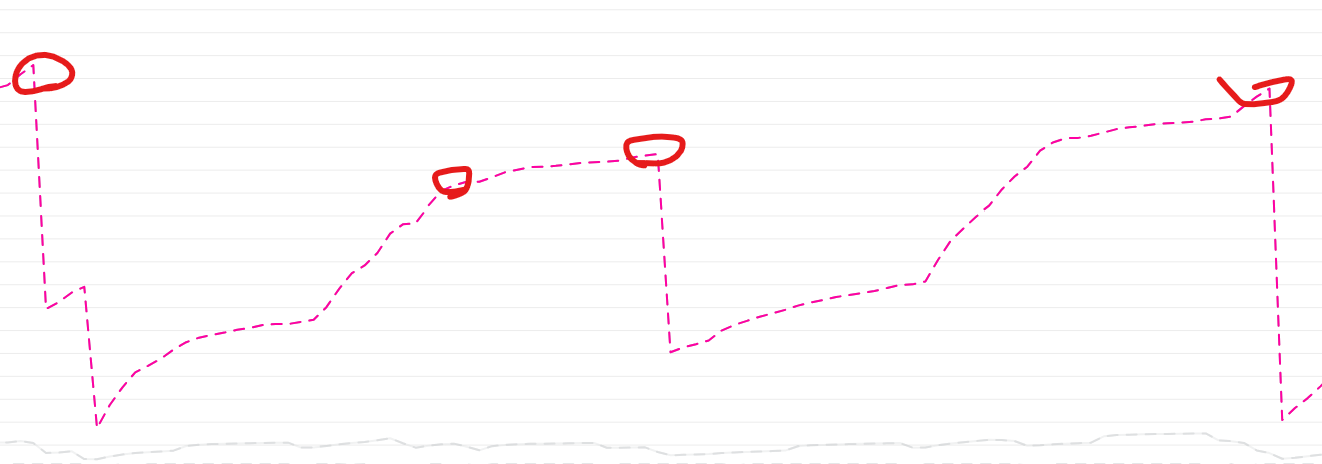
확실히 스레드의 개수가 높아진 시점과 OOM이 발생한 시점이 비슷해보인다.
운영 환경의 인증 서버의 경우 동일대 시간으로 봤을 때 대략 70개 전후의 스레드 개수에 비해
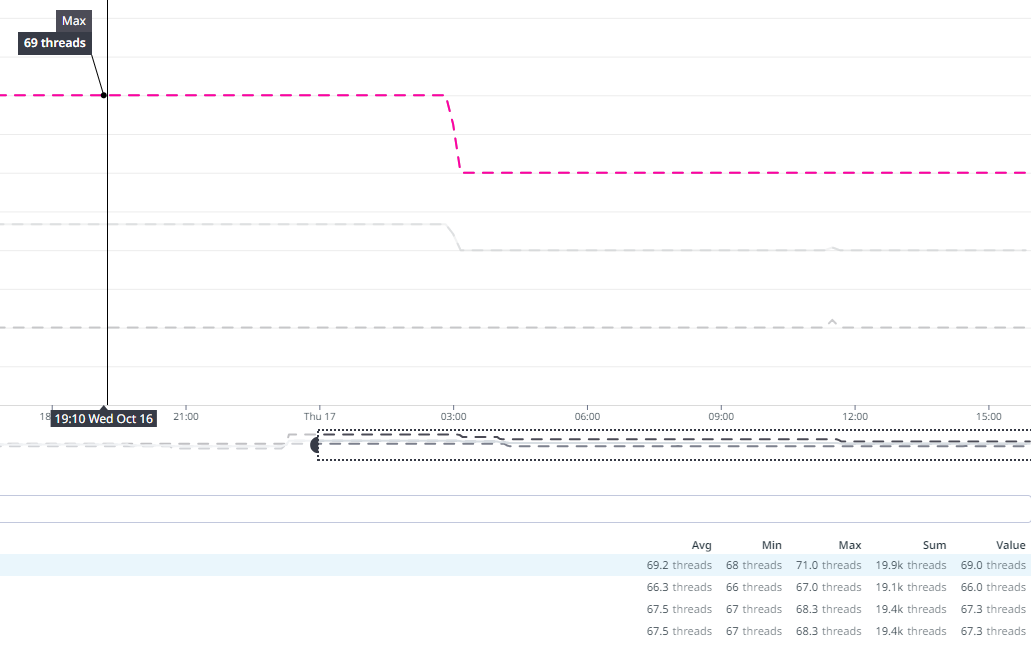
문제가 발생하는 회원 서버의 경우에는 최대 2.28k의 개수까지 치솟고 있는 것을 확인할 수 있었다.

단순히 개수가 많다고 해서 OOM과 연관이 있는 것은 아니나, 스레드는 일정 시간이 지나면(자신이 해야 할 일을 다 했다면) 회수 되어야 한다.
인증 서버의 경우 잠시 증가된 스레드는 일정 시간 후에 회수되고 있으나, 회원 서버 의 경우 회수되는 것에 비해 증가 폭이 큰 것을 볼 수 있었다.
만약 스레드가 회수되지 못해 메모리에 남게 된다면 OOM의 주 원인이 될 수 있다.
문제 재현을 위한 부하 테스트 환경 구성
⚙️ 테스트 도구 & 환경 세팅
- 부하 테스트: Apache JMeter
- JVM 모니터링: visualVM
- JVM 옵션: -Xmn100m -Xmx300m
인텔리제이 내부의 플러그인을 설치하여 간편하게 연동하여 사용할 수 있다.
(설치 및 연동은 이곳을 참고하자)
테스트 대상 API 분석 및 선정
메모리가 급증하는 구간과 평탄한 구간 마다 가장 많이 호출됐던 API 리스트를 뽑아봤을 때
거의 순위가 차이가 없음을 발견했다.
→ 갑작스러운 메모리 폭증보다는, 빈번한 호출로 인해 서서히 쌓이는 메모리 누수일 가능성이 높다고 판단.
최종 테스트 대상 API 3종:
- POST /v1/login
- POST /v1/auth/member/log/{memberLogType}
- GET /v1/auth/member
마지막으로 JMeter에 테스트 환경까지 구성해주면 테스트 진행 준비는 끝났다.

가장 자주 호출되는 login API부터 테스트했다.
100명의 유저(스레드)가 1초 안에 실행되고, 총 250회 반복.
결과는…
- Heap은 안정적
- GC는 Eden → Survivor에서 정상적으로 Minor GC 수행
- Old 영역 진입 없음
- 테스트 후 스레드 수 복구 OK
→ 1번 API는 범인 아님 확정!
2차 테스트: Member Log API에서 데드락이?
이 API는 로그인/로그아웃 등 이벤트 로그를 남기는 기능이다.
테스트 중간에 갑자기 발생한 데드락 로그…

💥 데드락 원인 분석
해당 API 내부 로직은 다음과 같다:
@Transactional
public MemberResponse.Result createMemberLog(...) {
member.updateLastLoginDateTime();
eventPublisherComponent.publishMemberEvent(...);
}그리고 로그 저장은 이렇게 처리하고 있었음
@TransactionalEventListener(phase = TransactionPhase.BEFORE_COMMIT)
public void logEvent(MemberLogDto memberLogDto) {
memberLogRepository.save(...);
}
데드락이 발생할 수 있는 이유는
- @TransactionalEventListener 의 BEFORE_COMMIT 으로 커밋 직전에 해당 logEvent메소드가 실행된다.
- MemberLog는 Member와 연관관계인 상태 (동일한 member를 참조할 수 있다.)
- 같은 트랜잭션 내부에서 아래와 같이 멤버를 수정하려고 할 때 데이터베이스에서 ‘잠금(Locking)’이 발생하면, MemberLog를 저장하려 할 때 동일한 테이블에 대한 잠금이 필요해질 수 있다
if(memberLogType.equals(MemberLogType.LOGIN)){
member.updateLastLoginDateTime();
} // ---> 여기서 1차적으로 Member 테이블에 접근하여 락이 걸리고
final MemberLog memberLog = memberLogDto.toEntity();
memberLogRepository.save(memberLog);
// ---> 로그 저장하는 시점에서 MemberLog와 연관관계인 Member 테이블에 접근하여 락이 걸림
( 실제로 운영환경에서도 데드락 이슈가 간간히 발생하고 있었다..! 🤯)
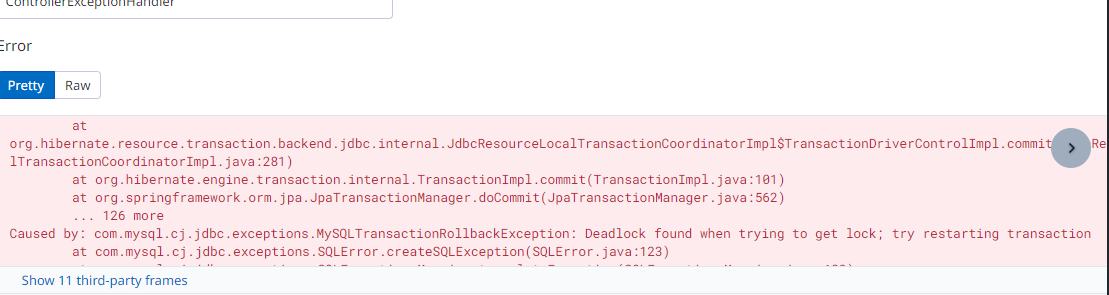
💡 데드락 해결을 위한 코드 수정
다음과 같이 트랜잭션 종료 후 비동기로 로그를 처리하도록 수정했다:
@Async
@Transactional
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void logEvent(MemberLogDto memberLogDto) {
memberLogRepository.save(...);
}
AFTER_COMMIT으로 바꾸고, 비동기로 처리하여 락 충돌 방지.
그런데... 또 Heap이 급등?
테스트를 다시 해보니 Heap이 급등하고, GC의 Old 영역도 확연히 증가하는 양상을 보였다
→ 데드락은 잡았지만 또 다른 문제가 숨어 있었다.
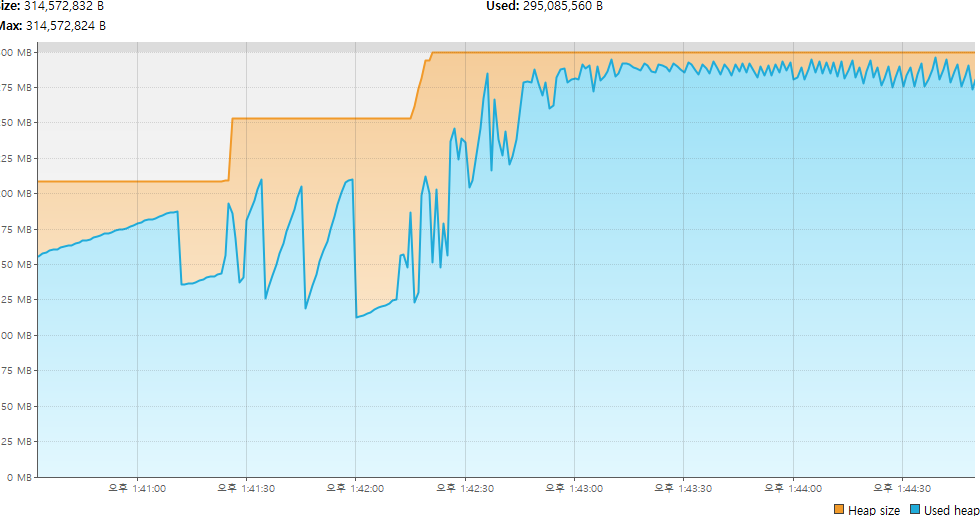
🔍 스레드 누수의 진짜 원인 - Async 설정
AsyncConfig를 살펴보니...
@Configuration
@EnableAsync
public class AsyncConfig implements AsyncConfigurer {
@Bean
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setTaskDecorator(new CustomDecorator());
return taskExecutor;
}
}
눈에 띈 문제점:
- corePoolSize, maxPoolSize, queueCapacity 설정 없음
- 스레드 종료 처리 없음
- RequestContextHolder를 통한 ThreadLocal 사용
- 비동기 종료 후 RequestAttributes 미정리
→ 스레드를 계속 생성하면서 회수가 안 되는 구조
→ RequestContextHolder가 스레드에 남아 있어서 누수 발생
✅ 최종 조치
부하 테스트를 통해 파악한 API에 대한 조치 내용은 다음과 같다.
1. 데드락 해결
@Component
@RequiredArgsConstructor
public class MemberLogListener {
private final MemberLogRepository memberLogRepository;
@Async
@Transactional
@TransactionalEventListener(phase = TransactionPhase.AFTER_COMMIT)
public void logEvent(MemberLogDto memberLogDto) {
final MemberLog memberLog = memberLogDto.toEntity();
memberLogRepository.save(memberLog);
}
}→ AFTER_COMMIT을 사용하여 트랜잭션이 끝난 후에 이벤트를 처리하도록 설정
@Async 와 함께 비동기 이벤트 처리를 사용하여 트랜잭션이 끝난 후 별도의 스레드에서 이벤트를 처리
2. @Async 설정 수정
@Bean
public Executor threadPoolTaskExecutor() {
ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor();
taskExecutor.setCorePoolSize(2);
taskExecutor.setMaxPoolSize(50);
taskExecutor.setQueueCapacity(500);
taskExecutor.setThreadNamePrefix("Async-");
taskExecutor.setTaskDecorator(new CustomDecorator());
return taskExecutor;
}→ 스레드 풀 관련 설정 추가
public class CustomDecorator implements TaskDecorator {
@Override
public Runnable decorate(@NotNull Runnable runnable) {
RequestAttributes requestAttributes = RequestContextHolder.getRequestAttributes();
return () -> {
try {
RequestContextHolder.setRequestAttributes(requestAttributes);
runnable.run();
} finally {
RequestContextHolder.resetRequestAttributes(); // 꼭 정리!!
}
};
}
}→ try-finally 작업을 통해 비동기 작업이 완료된 후, RequestAttributes를 정리하는 로직을 추가했음
🔁 테스트 결과
- Heap: 안정적, GC도 Minor에서 반복 처리 잘됨
- Old 영역 증가 없음
- 테스트 종료 후 스레드 수 정상 복구


😐 근데 찝찝한 점 하나
애초에 OOM이 났던 시점에는 @Async가 적용되지 않았다는 것
테스트 중 데드락 이슈를 고치면서 @Async가 붙었기 때문에, 이 조치가 진짜 OOM을 해결한 것인지는 아직 확신할 수 없다.
하지만 이 외에도 @Async를 사용하는 코드가 서비스 곳곳에 있었기 때문에
전체적으로 누적된 메모리가 있었을 가능성은 매우 크다고 판단.
→ 결국 실제 PR 환경에 배포하고 나서 계속 메모리 추이 관찰 예정
🤔 번외
모니터링 도구를 보면, 기동 후 아무것도 하지 않아도 주기적으로 힙 메모리가 쌓이고 줄어드는 모양이 반복된다? (like 바트 머리)
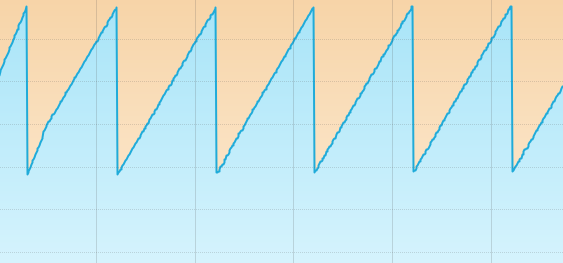
이건 JVM 내부의 백그라운드 GC 최적화로 인해 자연스럽게 발생하는 패턴이다.